
| Version 37 (modified by lchourio, 7 años ago) (diff) |
|---|
1. Modelado de tópicos
En las últimas décadas los avances informáticos y tecnológicos han traído consigo que los textos y documentos sean cada vez más numerosos y aparezcan más frecuentemente en formato electrónico. Esto imposibilita que la fuerza humana pueda ser capaz de analizarlos todos y cada uno de ellos, principalmente por la enorme cantidad de tiempo que se requiere invertir para procesar esta gran cantidad de información. Para solucionar este problema, se recurre a automatizar este proceso [1[.

El modelado de tópicos es una herramienta que facilita el procesamiento de conjuntos numerosos de textos o documentos electrónicos para analizar y clasificar su contenido, a través de un conjunto de técnicas estadísticas que permiten modelar las relaciones entre las palabras que componen estos documentos (o corpus). De esta manera, es posible reconocer cómo las palabras que conforman el corpus se agrupan en conjuntos que podemos identificar como tópicos o temas que pueden servir como criterio de organización del mismo.
1.1 Definición

Muchos investigadores se han dedicado a desarrollar el modelado de tópicos, que consiste en una serie de algoritmos que analizan grandes colecciones de documentos con alguna temática en particular (corpus). En otras palabras, el modelado de tópicos es un método que permite analizar las palabras de los documentos, aglomerarlas en temas (tópicos) y ver cuál es la relación entre palabras y tópicos.
- Corpus: Un corpus lingüístico es un conjunto de documentos o textos que presentan características formales comunes, lo que implica que pertenecen a un mismo género discursivo. Para considerar un conjunto de textos como pertenecientes a un corpus factible de analizar, como un todo, es necesario que los mismos puedan caracterizarse bajo un mismo género discursivo, además de otros posibles rasgos comunes entre los textos, por ejemplo, artículos científicos (de una misma disciplina o no), notas de prensa (de un periodo determinado, de un tema particular, o de un medio o periodista específico), poemas (de un periodo específico, de un mismo autor, o de un mismo tema).
- Tópicos: agrupación de palabras que con mayor frecuencia aparecen juntas, conformando un tema o tópico (http://www.martindoestheblog.com/2015/07/18/una-resena-sobre-lda/). En otras palabras, podemos entender los tópicos como los temas subayecentes al corpus o conjunto de documentos que analizamos. Tales tópicos permiten entrever las relaciones de proximidad o similitud entre un texto y otro.
Dentro del conjunto de métodos para modelar tópicos, están aquellos que utilizan la teoría de probabilidad para modelar la incertidumbre en los datos y son llamados modelos probabilísticos de tópicos. Estos modelos describen un conjunto de distribuciones de probabilidades posibles para un conjunto de datos observados y el objetivo es utilizar los datos observados para determinar la distribución que mejor describa estos datos.
- Probabilidad Es el conjunto de posibilidades de que un evento ocurra o no en un momento y tiempo determinado. Dichos eventos pueden ser medibles a trav´es de una escala de 0 a 1, donde el evento que no pueda ocurrir tiene una probabilidad de 0 (evento imposible) y un evento que ocurra con certeza es de 1 (evento cierto).
- Una Distribución de Probabilidad de una variable aleatoria X representa todos los valores posibles de X y las probabilidades de que cada valor posible ocurra. Denotaremos la distribución de probabilidad de una variable aleatoria X como P(X).
1.2 Herramientas
Herramientas para el modelado de tópicos
Para realizar el modelado de tópicos es necesario tener tres (3) herramientas
- Freeling
- LDA
- Nuestra herramienta Web
- Freeling: Es una o un conjunto de herramientas para análisis lingüístico, la cual es de código abierto y fue desarrollada por Lluís Padró, la misma es mantenida por TALP Research Center en la Universitat Politècnica de Catalunya. Podemos descargarlo en su Página Oficial [http://nlp.cs.upc.edu/freeling/node/30 Freeling]
- LDA: Es una implementación en C del algoritmo Latent Dirichlet Allocation (LDA), el cuál permite analizar corpus y extraer los tópicos que combinados forman el documento. Podemos descargarlo en su Página Oficial [http://www.cs.princeton.edu/~blei/lda-c/lda-c-dist.tgz LDA]. O nuestra versión compilada desde [https://planificacion.cenditel.gob.ve/trac/attachment/wiki/ModeladoTopicos_2017/herramientas/lda-c-dist_compilado.tar.gz aquí].
- Sistema de Modelado de Tópicos: Es una visualización interactiva de los resultados del LDA, basado en esta implementación de Github, pero migrado al proyecto al framework Django. El código fuente de la aplicación se encuentra en nuestros [https://planificacion.cenditel.gob.ve/trac/browser/modelado_topicos Repositorios].
Para mayor información sobre la instalación y configuración del Sistema de Modelado de Tópicos presione aquí
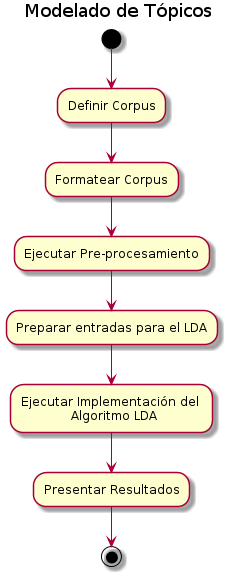
1.3 Metodología del Modelo LDA
Para el procesamiento de documentos se cuenta con el Latent Dirichlet Allocation (LDA), que es un modelo probabilístico para la colecciones de datos discretos, como un corpus de texto. El modelo LDA tiene un gran impacto dentro de los problemas de recuperación de información (en este caso obtención de tópicos), de ahí su gran importancia dentro de este ámbito.

1. Definir el corpus
Si bien un corpus puede estar compuesto por dos o más textos (técnicamente es un conjunto finito de documentos), en el caso particular de las posibilidades de análisis que brinda el LDA, esta pareciera adaptarse mejor al análisis de corpus amplios, que contengan un número considerablemente extenso de textos (las pruebas hasta ahora realizadas nos indican que el número de textos debe superar idealmente 1000 unidades, pudiendo tener una extensión breve cada una de ellas, como en el caso de las notas de prensa digital). La definición del corpus implica entonces identificar un conjunto finito de textos que puedan ser considerados como similares en sus características formales (un conjunto de artículos científicos, un conjunto de entrevistas abiertas realizadas en trabajo de campo, las respuestas abiertas de una consulta pública, un conjunto de notas de prensa digital, entre otros) y que para el análisis mediante la aplicación del LDA debe contener un número superior a 1000 textos. Estos textos deben cumplir con los requisitos de estar en formato de texto plano digital (txt) y estar agrupados en un mismo fichero para su procesamiento mediante el uso de LDA.
2. Formatear el corpus
Los textos deben encontrarse como se mencionó anteriormente en texto plano, para luego ser pre-procesados y formateados a posteriori de la ejecución del LDA.
3. Ejecutar el pre-procesamiento sobre el corpus
El pre-procesamiento es una acción mediante la cual una serie de algoritmos se encargan de limpiar los corpus y crear otros directorios/archivos necesarios para usar el algoritmo del LDA y visualizar los resultados en la interfaz.
El pre-procesamiento busca eliminar palabras que no aportan a la configuración de los tópicos o temas, por ejemplo, las palabras que cumplen una función más de tipo sintáctica (preposiciones, artículos, pronombres). También puede servir para eliminar palabras que por la naturaleza misma del corpus tienen una frecuencia de aparición demasiado alta, lo que hace que tampoco aporten a algún tópico en particular, por ejemplo palabras como decir, informar, indicar, señalar, tienen una frecuencia de aparición muy alta dentro de un corpus de tipo periodístico o mediático, por lo que resulta conveniente eliminarlas en el pre-procesamiento para tener una data depurada que permita apreciar mejor la configuración de los tópicos.
Dentro del pre-procesamiento, existe una sección en la que se configuran las formas gramaticales que se desean conservar en los corpus luego de pre-procesar, es decir, las que no se excluirán, ya que por omisión se descartan todas. Entre estas formas tenemos: verbos, adjetivos, sustantivos, adverbios, determinantes, pronombres, conjunciones, interjecciones.
El algoritmo que realiza el pre-procesamiento, también permite excluir palabras (que se deben conocer a priori) que no aportan ninguna carga lingüística para el análisis. Es importante resaltar que las palabras se excluyen literalmente como se colocan, es decir que si se excluye la palabra "pueblo" y en el corpus existe la palabra "pueblos" esta última no será excluida ya que está en plural y son palabras distintas.
4. Preparación de entradas para el algoritmo LDA
Este proceso es un paso intermedio que consiste en tomar algunas de las salidas del pre-procesamiento y generar archivos que servirán como entrada para la ejecución del LDA.
5. Ejecutar la implementación del algoritmo LDA
Para la implementación del algoritmo es necesario definir algunos parámetros de ejecución: cantidad de tópicos que se desean generar, ruta del archivo de configuración del LDA, ruta de los archivos pre-procesados, ruta de uno de los archivos generados por el paso intermedio (extensión .dat) y el nombre de la carpeta donde se generará la salida.
Con estos parámetros definidos, simplemente es necesario ejecutar el LDA, esperar a que se realice el procedimiento y visualizar la carpeta con los archivos correspondientes a la salida.
6. Presentar resultados del algoritmo LDA
Los resultados del LDA pueden ser visualizados mediante una interfaz web que presenta un diagrama de barras, constituido por la aparición de los tópicos (representados en colores distintos) en el corpus.
- Colocar una imagen de ejemplo
 Fuente: http://www.martindoestheblog.com/2015/07/18/una-resena-sobre-lda/
Fuente: http://www.martindoestheblog.com/2015/07/18/una-resena-sobre-lda/
1.4 Posibles usos
Las potencialidades de un sistema de este tipo pueden ser diversas. Por una parte, pueden ser útiles para el estudio de matrices discursivas contenidas en conjuntos de documentos como titulares de prensa y reportajes. Por lo tanto, puede contribuir con el estudio de matrices mediáticas o comunicacionales. En esta categoría, puede ser que el corpus se encuentre integrado por otro tipo de textos, como discursos políticos, entonces sería posible estudiar un buen número de alocuciones de una cierta tendencia para extraer los aspectos de significado más constantes.
Por otra parte, el modelado de tópicos puede ser útil para la investigación documental si se cuenta con un corpus de productos de investigación, tales como libros y artículos científicos. La importancia de los repositorios de publicaciones gubernamentales y universitarias podría incrementarse si contáramos con buscadores que no sólo extrajeran los títulos de los artículos, sino que además los analizaran entregándonos como resultado un conjunto de tópicos relevantes en función de los temas de interés en campos como la salud y la producción alimentaria.
Finalmente, en el área de diseño y evaluación de políticas públicas, el modelado de tópicos puede contribuir como herramienta de organización de documentos recogidos a partir de consultas públicas en las que los ciudadanos expresan sus opiniones en torno a varios temas. Por ejemplo, una consulta pública sobre una iniciativa legislativa o del Ejecutivo podría registrarse y analizarse eficientemente con ayuda de esta herramienta, además de que los textos pueden colocarse a disposición del público. Lo mismo sería válido para diferentes tipos de consulta a nivel nacional, estadal o municipal. Específicamente en el caso de la Planificación Operativa del año 2018 puede emplearse esta herramienta en dos momentos o escenarios:
- Primer momento: Una vez que las instituciones del Estado hayan cargado su explicación situacional en el SIPES, con la participación de las comunidades, el modelado de tópicos puede ser aplicado para que el los actores macro, en este caso, los ministerios, puedan observar los temas o tópicos relevantes de la situación de sus entes adscritos.

- Segundo momento: Una vez haya realizado el proceso de la carga de la explicación situacional, se puede realizar una consulta pública a través de un sistema en línea que permita validar la información reflejada por los entes y que permita considerar la opinión de las personas consultadas. En este sentido el sistema puede ayudar a analizar el resultado de la consulta pública y su influencia en la explicación situacional que ya se tenía.

Resultados de la aplicación de las herramientas
Con el fin de entender mejor el funcionamiento del LDA para el análisis de corpus lingüísticos, diseñamos y aplicamos un protocolo de análisis piloto para tres (2) corpus de naturaleza discursiva distinta, que nos permitieran entrever posibles diferencias en los resultados que apunten a identificar categorías discursivas que puedan ser analizadas mediante la aplicación del LDA a corpus amplios.
A continuación detallaremos cada corpus de análisis, así como los rasgos discursivos que consideramos de interés a partir de los resultados obtenidos en el análisis mediante el uso del LDA.
1. Plan de la Patria
I. Definición del corpus
A partir de la consulta pública constituyente convocada por el Presidente Hugo Chávez en el año 2012 en torno a la propuesta del Plan de la Patria (2013-2019) se constituyó un corpus de análisis conformado por 4.634 consultas recibidas mediante el sistema de consulta pública digital. Este sistema solicitaba al usuario (individuo o colectivo) completar una serie de campos (de identificación y relativos a la propuesta a subscribir) que le permitían desarrollar una propuesta que pudiera ser incorporada como parte del Plan Nacional de Desarrollo de la Nación, Plan de la Patria.
Las consultas recibidas en este proceso presentan una serie de características textuales y discursivas comunes que nos permiten considerarlas un conjunto de textos factibles de analizar en tanto corpus. Las mismas son muestras de habla escrita, con rasgos de formalidad, dada la situación de habla institucional en la que se enmarcan, y generalmente desarrollan uno o dos tópicos semánticos, por cuanto se solicitaba como parte de la consulta que se identificara un objetivo general del Plan de la Patria con el cual se relacionaba la propuesta a realizar mediante el sistema de consulta y esto restringe generalmente el campo semántico a desarrollar.
II. Preprocesamiento del Corpus
El procedimiento correspondiente al preprocesamiento de los corpus viene dado por un script diseñado en python, que contiene una serie de configuraciones que indican cómo se debe procesar los textos antes de ser ingresados a una librería llamada freeling. Esta configuración consiste en listar los elementos textuales que se deben excluir antes de ser procesado. En este apartado tenemos las categorías: verbos, adjetivos, sustantivos, adverbios, determinantes, pronombres, conjunciones, interjecciones y preposiciones, de las cuales generalmente se excluyen por razones de relevancia semántica los pronombres, conjunciones, interjecciones, preposiciones y adverbios.
Una vez hecho esto la librería se encarga de procesar y arrojar los resultados en un formato que luego será interpretado por el LDA y cuya interpretación se ve representada en la interfaz gráfica que se dispone a mostrar al usuario. La interfaz de usuario proviene de un proyecto en github, perteneciente a un desarrollador de la universidad de Indiana, el cual implementa la visualización de datos del LDA en el framework VSM. En este sentido, se consideró cambiar esta implementación por un framework más robusto como lo es Django y poder así adaptarlo a las necesidades pertinentes de nuestro contexto tanto político como social.
Es importante destacar que la implementación del VSM trabajaba por defecto con una implementación de LDA basada en el muestreo de Gibbs (modelo con el que se estuvo trabajando en un principio y por la naturaleza de los resultados se intuye que convergía), por lo que con colaboración de algunos scripts realizados por Jamie Murdock (autor del proyecto en github), más algunos de autoría de Jorge Redondo se pudieron traer resultados del LDA-C (LDA de Blei) a la interfaz. Cabe destacar que estos resultados eran mejores que los presentados anteriormente por los del muestreo de Gibbs.
El cambio más importante a nivel de visualización con respecto al proyecto original fue la implementación que permitió ver la estructura de cada de uno de los corpus por separado, y a su vez permitir ver a través de una nube de palabras la relevancia de cada palabra dentro de los tópicos que constituyen el corpus seleccionado, es decir que entre más porcentaje (determinado por el LDA) tenga una palabra en el tópico, mayor será su tamaño en la nube de palabras.
III. Resultados
Los resultados obtenidos mediante la aplicación del LDA al procesamiento del corpus Plan de la Patria mostraron consistencia semántica en la identificación de los tópicos relevantes dentro del corpus, así como en la identificación de la relevancia de las propuestas dentro de cada tópico (por su grado de proximidad semántica con respecto al tópico), y la identificación de la relevancia de cada palabra dentro de los tópicos.
Se obtuvieron resultados que permitieron identificar desde los 10 hasta tópicos más relevantes hasta 90 tópicos, lo que resulta de gran utilidad en un corpus tan amplio y de naturaleza semántica tan diversa como un consulta pública relativa al Plan Nacional de Desarrollo, lo que contempla todas las áreas de competencia del Estado y las áreas de interés de las y los ciudadanos.
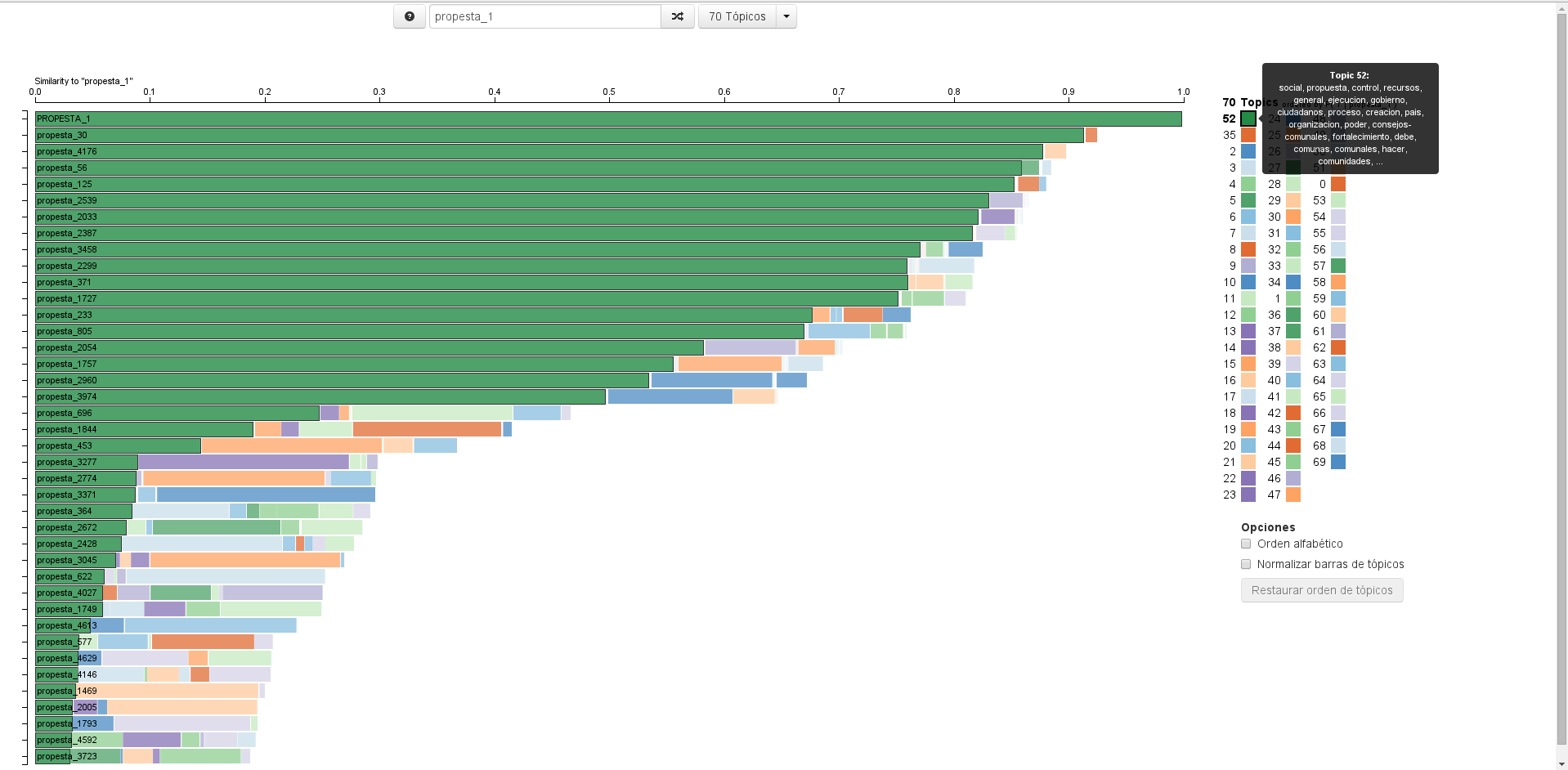
En la figura 1 se puede apreciar la visualización de los resultados del análisis del Corpus Plan de la Patria identificando 70 tópicos.
Figura 1
Mediante la herramienta de visualización es factible seleccionar un tópico, en este caso el tópico 52 (social, propuesta, general, ejecución, gobierno, ciudadanos, proceso, creación, país, organización, poder, consejos comunales, fortalecimiento, debe, comunas, comunales, hacer, comunidades…), y ordenar los textos que componen el corpus de acuerdo con la relevancia que tenga ese tópico en cada uno de los textos. En este caso la propuesta_1 es el documento más relevante para el tópico 52.
En la figura 2 podemos apreciar la visualización de la relevancia de cada palabra dentro de un texto, en este caso la propuesta_1.
Figura 2
Esta interface permite identificar rápidamente mediante el uso de colores el tópico de pertenencia de cada palabra identificada como perteneciente aun tópico dentro de la propuesta, lo que resulta útil al momento de identificar relaciones semánticas entre los textos que componen el corpus. Igualmente, el tamaño de la palabra dentro del texto nos indica la relevancia del término a lo interno del tópico al que pertenece, esto es su frecuencia de aparición dentro del tópico.
- Medios digitales
- Definición del corpus
A fines de constituir un corpus factible para probar el funcionamiento del modelado de tópicos mediante el uso del algoritmo LDA en el análisis de medios de comunicación digitales en Venezuela, se definió un periodo comprendido entre el 17 y 18 de febrero de 2016. Tal periodo se definió tomando en cuenta la alocución presidencial del día 17 de febrero en la que el Presidente de la República Nicolás Maduro y su gabinete ministerial anunciaron una serie de medidas económicas de alto impacto en la vida nacional, lo que se identificó como un evento comunicacional de alta repercusión en la agenda mediática del país. Este evento genera un parámetro claro, tanto para la definición del corpus de estudio, como para la evaluación de la eficacia de la herramienta para el análisis de discurso mediático, al poder comprobar en los resultados del análisis si el LDA modela los tópicos relativos a los temas presentados en tal evento comunicacional, que se espera sean los temas más recurrentes en la agenda de los medios nacionales. El corpus está constituido enteramente por notas de prensa digitales, cuyo formato textual generalmente conserva una tipología definida por ser un tipo de texto formal, conciso (un promedio de dos párrafos por nota), en el que se desarrolla uno o dos temas generales en promedio.
- Automatización de la compilación del corpus
Se diseñó una herramienta de web scrapping para la recolección automatizada de las notas de prensa identificadas como publicadas en el periodo definido. Para tal fin, se identificó las secciones de Nacionales, Políticas y Economía como las de interés para el análisis, excluyendo así las demás secciones de los medios a analizar. Se seleccionó un grupo de cinco (5) medios digitales de relevancia nacional, con el propósito de normalizar la identificación tanto de la fecha como de la sección de publicación de la nota. Se obtuvo de esta manera un corpus de 915 notas de medios digitales publicadas entre el 17 y 18 de febrero en las secciones nacional, política y economía que esperábamos mostraran principalmente los temas abordados en los anuncios económicos gubernamentales. La herramienta de web scrapping se desarrolló usando un framework de Python llamado Scrapy, el cual esta diseñado precisamente para esa tarea. Es importante resaltar que para poder realizar scrapping a una web es necesario conocer con antelación la estructura del sitio web a inspeccionar, hecho esto se procede a crear un araña (término que se le da a un programa que inspecciona una web de manera automatizada) con las configuraciones correspondientes al sitio del que se extraerá la información, por lo que es importante resaltar que debido a la diversidad de los sitios de noticias es preferible contar con una araña personalizada que se adapte a las necesidades especificas de un sitio, de modo que si el mismo cambia con el tiempo, el único código que se vería afectado es el de la araña correspondiente. Los principales parámetros que se deben considerar son las URL's o direcciones del sitio que se desean explorar, las categorías que se desean tomar en cuenta y lo más importante y que conlleva más trabajo es conocer la estructura de los artículos para así proceder a la extracción de la información que los conforman. Para el trabajo planteado en particular fue necesario plantearse dos parámetros en particular, la fecha de inicio y la fecha de fin, es decir el intervalo del que se extraerá la información. Otro punto relevante con los medios digitales, es que la estructura de los sitios web se deben prestar para el scrapping, lo que se puede resumir para este caso en 3 aspectos: El primero es que el sitio tenga sus noticias clasificadas por categorías (es algo elemental en toda noticia, pero hay sitios que no lo hacen), segundo que tengan en sus páginas de categorías un historial (es decir, la data histórica de todas las noticias que se han publicado, por lo general en una tabla), se puede citar el ejemplo de El Universal, que no lo hace por ejemplo en ninguna categoría; el tercer y último aspecto es que en caso de que la tabla cargue de forma dinámica (Ajax por lo general) es necesario consultar a las URL que hace petición el servidor para traerse los datos, y algunos sitios manejan autenticación para poder acceder a dichas URL'S. Ahora entrando en materia sobre el procedimiento que se realizó para extraer el material de los medios digitales se puede resumir en los siguientes pasos: Crear la araña y configurarlas con URL's del sitio Configurar los parámetros para extraer la información (se especifica de donde se extraerá el autor, titulo, fecha, cuerpo de la noticia, etc) Se corre por consola la araña pasando por parámetro el intervalo de las fechas que se desea buscar Al finalizar el scrapping la araña crea un archivo en formato .json con los resultados de todos los medios Nota: Como la araña en si busca por la tabla que se encuentra en la sección especificada, a modo de reducir los tiempos de espera se puede configurar dentro de la araña desde que página a que página se debe buscar (obviamente conociendo dicho intervalo a priori)
Una vez realizado el scrapping es necesario transformar los archivos .json que arroja como salida en archivos de texto plano que puedan ser tratados por el preprocesamiento, tarea que se realizó con un script en python. Es importante que los tiempos de espera son cortos, pero a su vez van relacionados con los servidores en los que estén alojados los sitios, como ejemplo de guía: Si se establecen a priori las páginas, un scrapping con una conexión promedio a un sitio con una velocidad promedio puede tardar de 2min a 5min, ahora sin conocer a priori las páginas y tomando en cuenta unas fechas como las analizadas (febrero), digamos una noticia de unos 3-4 meses de anterioridad, dependiendo del flujo de noticias que tenga el sitio, se puede estimar que el tiempo de espero podría ser de 15-30min. Ahora el tiempo que tarda el script en convertir .json en texto plano, son milésimas de segundos, si son muchos datos a procesar tal vez unos pocos segundos, en general nada de que preocuparse.
- Preprocesamiento del corpus
A partir de una primera corrida de los textos compilados se pudo identificar una serie de términos de frecuente aparición a lo largo de todos los tópicos y que son característicos del tipo de género discursivo periodístico. Estas palabras se identificaron y seleccionaros para ser excluidas junto con el preprocesamiento estandar del texto que excluye palabras de bajo interés para el análisis por su naturaleza gramatica (preposiciones, artículos, adverbios).
Preprocesamiento de discurso periodístico
Sustantivos País Venezuela Año Día Caracas Ayer
Adjetivos Venezolano
Verbos Haber Decir Hablar Explicar Indicar Asegurar Aseverar Anunciar Realizar Informar Calificar Poner Querer Presentar Seguir Llevar Expresar Manifestar Considerar Afirmar Destacar Señalar Referir Llamar Agregar Publicar Poder
- Resultados
A partir de este piloto de análisis automatizado mediante el uso de LDA del corpus constituido por cerca de mil notas digitales de cinco medios venezolanos se obtuvo resultados de interés que nos permiten entrever la pertinencia del uso de esta herramienta para la automatización de procesos de análisis de medios de comunicación digital.
El análisis del corpus arrojó los siguientes datos para la visualización de diez tópicos:
10 Tópicos Tópico 3 – Comisión de contraloría de la AN investiga por corrupción a altos funcionarios del gobierno Tópico 1 – Aumento precio gasolina, precio petróleo, sistema cambiario Tópico 2 – Guyana, Ginebra, Asamblea Tópico 4 – Leopoldo López Tópico 5 – Visita premio Nóbel de la Paz – Leopoldo López Tópico 6 – Ley de Amnistia Tópico 7 – Medidas económicas / modelo económico Tópico 8 – No identificado claramente / relativo a medidas económicas Tópico 9 - No identificado claramente / relativo a medidas económicas Tópico 0 - No identificado claramente / relativo a medidas económicas
Estos resultados muestran el tópico principal de las medidas anunciadas por el Presidente Nicolás Maduro en el periodo seleccionado, desplegado en dos subtópicos (Tópicos 1 y 7), y además muestran tópicos políticos de la agenda mediática de la oposición venezolana recogidos por los medios digitales (tópicos 2, 4, 5, y 6). Tales resultados permiten entrever que la herramienta de modelado de tópicos resulta pertinente para la automatización de análisis discursivo de medios de comunicación digital, cuyo formato textual y temático se comporta adecuadamente con el modelo del LDA.
REFERENCIAS
- Guía Teórica del Proyecto Modelado de Tópicos CENDITEL 22 de julio de 2016
- http://www.martindoestheblog.com/2015/07/18/una-resena-sobre-lda/
LAS IMÁGENES USADAS SON REFERENCIALES
Adjuntos (8)
- plantuml.png (17.9 KB) - added by lchourio 7 años ago.
- Big_Data_concept_cloud_and_devices.png (127.7 KB) - added by lchourio 7 años ago.
- WordCloud1.png (158.0 KB) - added by lchourio 7 años ago.
- proceso.png (67.1 KB) - added by lchourio 7 años ago.
- entes.jpg (7.8 KB) - added by lchourio 7 años ago.
- consulta.png (18.2 KB) - added by lchourio 7 años ago.
- Figura1.png (100.8 KB) - added by lchourio 7 años ago.
- Figura2.png (386.1 KB) - added by lchourio 7 años ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip