
| Version 28 (modified by lchourio, 7 años ago) (diff) |
|---|
1. Modelado de tópicos
En las últimas décadas los avances informáticos y tecnológicos han traído consigo que los textos y documentos sean cada vez más numerosos y aparezcan más frecuentemente en formato electrónico. Esto imposibilita que la fuerza humana pueda ser capaz de analizarlos todos y cada uno de ellos, principalmente por la enorme cantidad de tiempo que se requiere invertir para procesar esta gran cantidad de información. Para solucionar este problema, se recurre a automatizar este proceso [1[.

El modelado de tópicos es una herramienta que facilita el procesamiento de conjuntos numerosos de textos o documentos electrónicos para analizar y clasificar su contenido, a través de un conjunto de técnicas estadísticas que permiten modelar las relaciones entre las palabras que componen estos documentos (o corpus). De esta manera, es posible reconocer cómo las palabras que conforman el corpus se agrupan en conjuntos que podemos identificar como tópicos o temas que pueden servir como criterio de organización del mismo.
1.1 Definición

Muchos investigadores se han dedicado a desarrollar el modelado de tópicos, que consiste en una serie de algoritmos que analizan grandes colecciones de documentos con alguna temática en particular. En otras palabras, el modelado de tópicos es un método que permite analizar las palabras de los documentos, aglomerarlas en tópicos y ver cuál es la relación entre palabras y tópicos, incluso permite determinar si estos cambian en el tiempo.
- Corpus: Un corpus lingüístico es un conjunto de documentos o textos que presentan características formales comunes, lo que implica que pertenecen a un mismo género discursivo. Para considerar un conjunto de textos como pertenecientes a un corpus factible de analizar, como un todo, es necesario que los mismos puedan caracterizarse bajo un mismo género discursivo, además de otros posibles rasgos comunes entre los textos, por ejemplo, artículos científicos (de una misma disciplina o no), notas de prensa (de un periodo determinado, de un tema particular, o de un medio o periodista específico), poemas (de un periodo específico, de un mismo autor, o de un mismo tema).
- Tópicos: agrupación de palabras que con mayor frecuencia aparecen juntas, conformando un tema o tópico (http://www.martindoestheblog.com/2015/07/18/una-resena-sobre-lda/). En otras palabras, podemos entender los tópicos como los temas subayecentes al corpus o conjunto de documentos que analizamos. Tales tópicos permiten entrever las relaciones de proximidad o similitud entre un texto y otro.
Dentro del conjunto de métodos para modelar tópicos, están aquellos que utilizan la teoría de probabilidad para modelar la incertidumbre en los datos y son llamados modelos probabilísticos de tópicos. Estos modelos describen un conjunto de distribuciones de probabilidades posibles para un conjunto de datos observados y el objetivo es utilizar los datos observados para determinar la distribución que mejor describa estos datos.
- Probabilidad Es el conjunto de posibilidades de que un evento ocurra o no en un momento y tiempo determinado. Dichos eventos pueden ser medibles a trav´es de una escala de 0 a 1, donde el evento que no pueda ocurrir tiene una probabilidad de 0 (evento imposible) y un evento que ocurra con certeza es de 1 (evento cierto).
- Una Distribución de Probabilidad de una variable aleatoria X representa todos los valores posibles de X y las probabilidades de que cada valor posible ocurra. Denotaremos la distribución de probabilidad de una variable aleatoria X como P(X).
1.1.3 Metodología del Modelo LDA
Para el procesamiento de documentos se cuenta con el Latent Dirichlet Allocation (LDA), que es un modelo probabilístico para la colecciones de datos discretos, como un corpus de texto. El modelo LDA tiene un gran impacto dentro de los problemas de recuperación de información (en este caso obtención de tópicos), de ahí su gran importancia dentro de este ámbito.
- El LDA maneja el modelo bayesiano jerárquico, en el que cada elemento de una corpus es modelada como una mezcla finita, sobre un conjunto fundamental de tópicos, donde a su vez cada tópico, modela como una mezcla infinita sobre un conjunto subyacente de tópicos probables, es decir, que todos los corpus se representan como mezclas aleatorias, sobre tópicos ocultos. Donde se caracteriza cada tópico por una distribución de varias palabras. LDA se presentó por primera como un modelo gráfico para la detección de tópicos y fue desarrollado por David Blei, Andrew Ng, y Michael Jordan en 2002 [1]. Por ejemplo, un modelo LDA podría tener los tópicos gato y perro. El tópico GATO tiene probabilidades de generar varias palabras: leche, maullido, gatito, por lógica la palabra gato tendrá la probabilidad más alta dado este tópico. Por otro lado, el tópico PERRO tiene la probabilidad de generar las palabras: cachorro, ladrido, hueso, y esta última podría tener una alta probabilidad.(chrome-extension://bpmcpldpdmajfigpchkicefoigmkfalc/views/app.html)

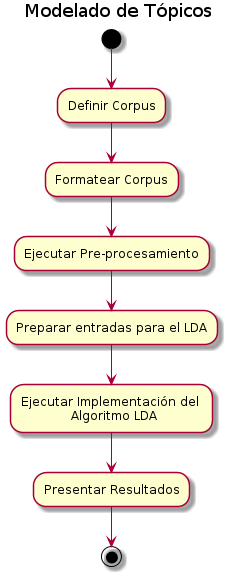
1. Definir el corpus
Si bien un corpus puede estar compuesto por dos o más textos (técnicamente es un conjunto finito de documentos), en el caso particular de las posibilidades de análisis que brinda el LDA, esta pareciera adaptarse mejor al análisis de corpus amplios, que contengan un número considerablemente extenso de textos (las pruebas hasta ahora realizadas nos indican que el número de textos debe superar idealmente 1000 unidades, pudiendo tener una extensión breve cada una de ellas, como en el caso de las notas de prensa digital). La definición del corpus implica entonces identificar un conjunto finito de textos que puedan ser considerados como similares en sus características formales (un conjunto de artículos científicos, un conjunto de entrevistas abiertas realizadas en trabajo de campo, las respuestas abiertas de una consulta pública, un conjunto de notas de prensa digital, entre otros) y que para el análisis mediante la aplicación del LDA debe contener un número superior a 1000 textos. Estos textos deben cumplir con los requisitos de estar en formato de texto plano digital (txt) y estar agrupados en un mismo fichero para su procesamiento mediante el uso de LDA.
2. Formatear el corpus
Los textos deben encontrarse como se mencionó anteriormente en texto plano, para luego ser pre-procesados y formateados a posteriori de la ejecución del LDA.
3. Ejecutar el pre-procesamiento sobre el corpus
El pre-procesamiento es una acción mediante la cual una serie de algoritmos se encargan de limpiar los corpus y crear otros directorios/archivos necesarios para usar el algoritmo del LDA y visualizar los resultados en la interfaz.
El pre-procesamiento busca eliminar palabras que no aportan a la configuración de los tópicos o temas, por ejemplo, las palabras que cumplen una función más de tipo sintáctica (preposiciones, artículos, pronombres). También puede servir para eliminar palabras que por la naturaleza misma del corpus tienen una frecuencia de aparición demasiado alta, lo que hace que tampoco aporten a algún tópico en particular, por ejemplo palabras como decir, informar, indicar, señalar, tienen una frecuencia de aparición muy alta dentro de un corpus de tipo periodístico o mediático, por lo que resulta conveniente eliminarlas en el pre-procesamiento para tener una data depurada que permita apreciar mejor la configuración de los tópicos.
Dentro del pre-procesamiento, existe una sección en la que se configuran las formas gramaticales que se desean conservar en los corpus luego de pre-procesar, es decir, las que no se excluirán, ya que por omisión se descartan todas. Entre estas formas tenemos: verbos, adjetivos, sustantivos, adverbios, determinantes, pronombres, conjunciones, interjecciones.
El algoritmo que realiza el pre-procesamiento, también permite excluir palabras (que se deben conocer a priori) que no aportan ninguna carga lingüística para el análisis. Es importante resaltar que las palabras se excluyen literalmente como se colocan, es decir que si se excluye la palabra "pueblo" y en el corpus existe la palabra "pueblos" esta última no será excluida ya que está en plural y son palabras distintas.
4. Preparación de entradas para el algoritmo LDA
Este proceso es un paso intermedio que consiste en tomar algunas de las salidas del pre-procesamiento y generar archivos que servirán como entrada para la ejecución del LDA.
5. Ejecutar la implementación del algoritmo LDA
Para la implementación del algoritmo es necesario definir algunos parámetros de ejecución: cantidad de tópicos que se desean generar, ruta del archivo de configuración del LDA, ruta de los archivos pre-procesados, ruta de uno de los archivos generados por el paso intermedio (extensión .dat) y el nombre de la carpeta donde se generará la salida.
Con estos parámetros definidos, simplemente es necesario ejecutar el LDA, esperar a que se realice el procedimiento y visualizar la carpeta con los archivos correspondientes a la salida.
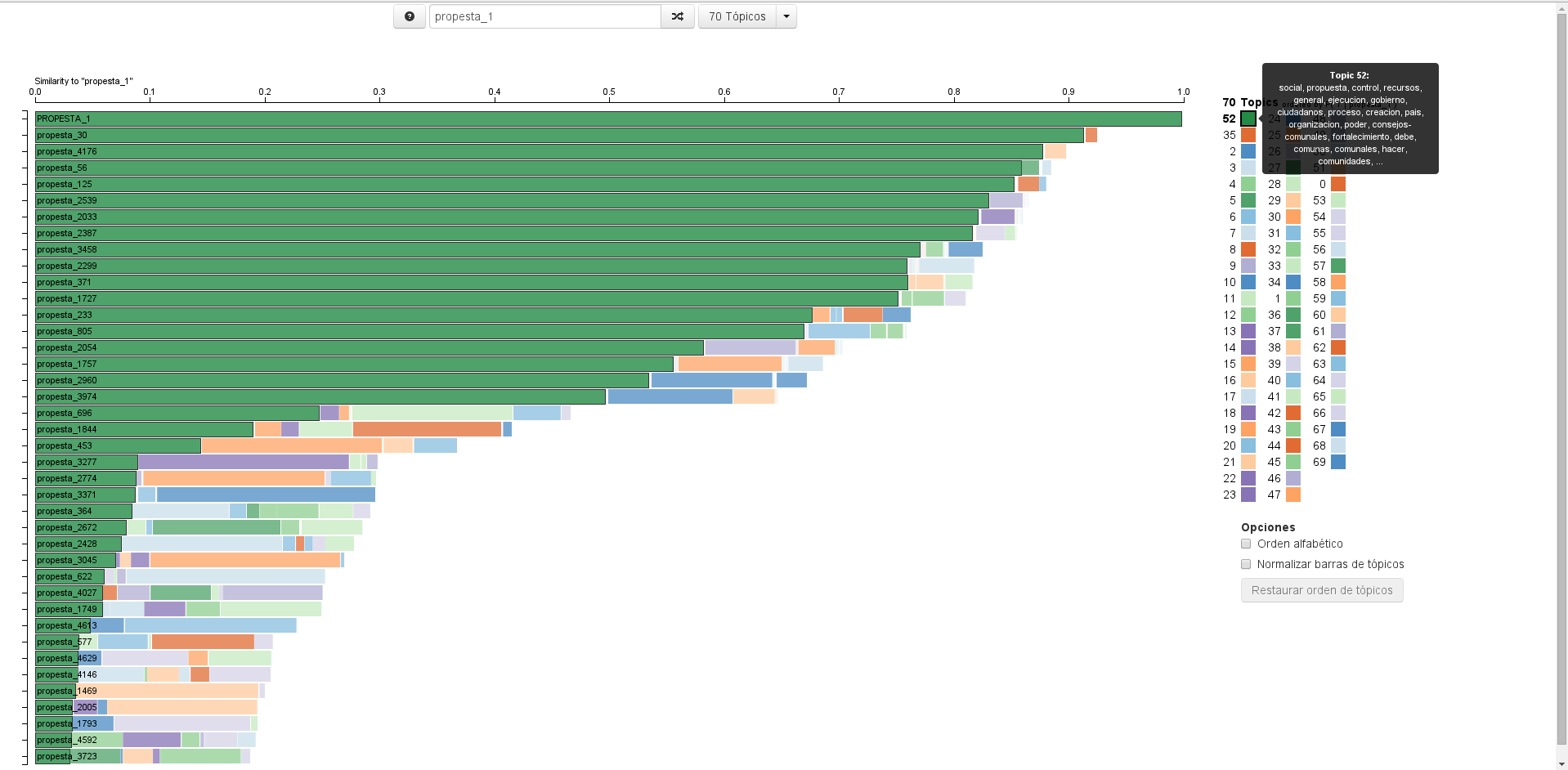
6. Presentar resultados del algoritmo LDA
Los resultados del LDA pueden ser visualizados mediante una interfaz web que presenta un diagrama de barras, constituido por la aparición de los tópicos (representados en colores distintos) en el corpus.
- Colocar una imagen de ejemplo
1.1.4 Herramientas
Herramientas para el modelado de tópicos
Para realizar el modelado de tópicos es necesario tener tres (3) herramientas
- Freeling
- LDA
- Nuestra herramienta Web
- Freeling: Es una o un conjunto de herramientas para análisis lingüístico, la cual es de código abierto y fue desarrollada por Lluís Padró, la misma es mantenida por TALP Research Center en la Universitat Politècnica de Catalunya. Podemos descargarlo en su Página Oficial [http://nlp.cs.upc.edu/freeling/node/30 Freeling]
- LDA: Es una implementación en C del algoritmo Latent Dirichlet Allocation (LDA), el cuál permite analizar corpus y extraer los tópicos que combinados forman el documento. Podemos descargarlo en su Página Oficial [http://www.cs.princeton.edu/~blei/lda-c/lda-c-dist.tgz LDA]. O nuestra versión compilada desde [https://planificacion.cenditel.gob.ve/trac/attachment/wiki/ModeladoTopicos_2017/herramientas/lda-c-dist_compilado.tar.gz aquí].
- Sistema de Modelado de Tópicos: Es una visualización interactiva de los resultados del LDA, basado en esta implementación de Github, pero migrado al proyecto al framework Django. El código fuente de la aplicación se encuentra en nuestros [https://planificacion.cenditel.gob.ve/trac/browser/modelado_topicos Repositorios].
Para mayor información sobre la instalación y configuración del Sistema de Modelado de Tópicos presione aquí
1.1.5 Posibles usos
Las potencialidades de un sistema de este tipo pueden ser diversas. Por una parte, pueden ser útiles para el estudio de matrices discursivas contenidas en conjuntos de documentos como titulares de prensa y reportajes. Por lo tanto, puede contribuir con el estudio de matrices mediáticas o comunicacionales. En esta categoría, puede ser que el corpus se encuentre integrado por otro tipo de textos, como discursos políticos, entonces sería posible estudiar un buen número de alocuciones de una cierta tendencia para extraer los aspectos de significado más constantes.
Por otra parte, el modelado de tópicos puede ser útil para la investigación documental si se cuenta con un corpus de productos de investigación, tales como libros y artículos científicos. La importancia de los repositorios de publicaciones gubernamentales y universitarias podría incrementarse si contáramos con buscadores que no sólo extrajeran los títulos de los artículos, sino que además los analizaran entregándonos como resultado un conjunto de tópicos relevantes en función de los temas de interés en campos como la salud y la producción alimentaria.
Finalmente, en el área de diseño y evaluación de políticas públicas, el modelado de tópicos puede contribuir como herramienta de organización de documentos recogidos a partir de consultas públicas en las que los ciudadanos expresan sus opiniones en torno a varios temas. Por ejemplo, una consulta pública sobre una iniciativa legislativa o del Ejecutivo podría registrarse y analizarse eficientemente con ayuda de esta herramienta, además de que los textos pueden colocarse a disposición del público. Lo mismo sería válido para diferentes tipos de consulta a nivel nacional, estadal o municipal. Específicamente en el caso de la Planificación Operativa del año 2018 puede emplearse esta herramienta en dos momentos o escenarios:
Primer momento: Una vez que las instituciones del Estado hayan cargado su explicación situacional en el SIPES, con la participación de las comunidades, el modelado de tópicos puede ser aplicado para que el los actores macro, en este caso, los ministerios, puedan observar los temas o tópicos relevantes de la situación de sus entes adscritos.
Segundo momento: Una vez haya realizado el proceso de la carga de la explicación situacional, se puede realizar una consulta pública a través de un sistema en línea que permita validar la información reflejada por los entes y que permita considerar la opinión de las personas consultadas. En este sentido el sistema puede ayudar a analizar el resultado de la consulta pública y su influencia en la explicación situacional que ya se tenía.
REFERENCIAS
- Guía Teórica del Proyecto Modelado de Tópicos CENDITEL 22 de julio de 2016
Adjuntos (8)
- plantuml.png (17.9 KB) - added by lchourio 7 años ago.
- Big_Data_concept_cloud_and_devices.png (127.7 KB) - added by lchourio 7 años ago.
- WordCloud1.png (158.0 KB) - added by lchourio 7 años ago.
- proceso.png (67.1 KB) - added by lchourio 7 años ago.
- entes.jpg (7.8 KB) - added by lchourio 7 años ago.
- consulta.png (18.2 KB) - added by lchourio 7 años ago.
- Figura1.png (100.8 KB) - added by lchourio 7 años ago.
- Figura2.png (386.1 KB) - added by lchourio 7 años ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip