
| Version 4 (modified by lchourio, 7 años ago) (diff) |
|---|
1. Análisis discursivo
vamos a necesitar tres cosas primero tenemos que alimentar el conocimiento a la máquina que sea leer toneladas de cosas segundo tendrá que tener cuidado con las palabras que usamos ya que son las características que cuidan la información y, finalmente, Necesitará cerciorarse de que el conocimiento es cortado En los trozos de tamaño adecuado ya que esto determinará el contexto dentro del cual se conectarán las palabras como para
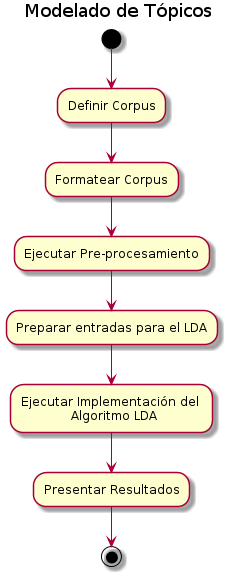
1.1 Modelado de tópicos
1.1.2 Definición
- Tópicos
- Corpus
1.1.3 LDA - Metodología
1.1.4 Herramientas
- Instalación
- Configuración
- Pre-procesamiento
1.1.5 Posibles usos
- Consulta pública Proceso escenarios
TRaducción Hola a todo el mundo Estoy entendiendo este palacio y voy a estar hablando de LDA un tema modelos i primero se topó con el tema de modelado cuando estaba trabajando en cuestión estrella Dana que actualmente es el más rápido crecimiento de la plataforma de publicación en línea mi tarea principal es el primer científico de datos En la empresa fue para construir un modelo de tema Lda, por supuesto, no voy a estar compartiendo un detalles íntimos sobre los problemas de aplicación en concreto en lugar de lo que voy a hablar de la idea detrás de la propia AOD ¿por qué funciona cuáles son las herramientas y marcos que pueden Ser utilizado aquí Lo que llevó a un parámetro es un ajuste de lo que significan en términos de su caso de uso específico y qué buscar cuando se evalúe como una empresa hizo su nombre mediante la creación de una hermosa experiencia de lectura en línea que cargar su PDF y se transforma en Dormir limpio publicación digital es bastante impresionante, pero que no es donde la base de lectores leal y monetizing se está construyendo tema tiene toneladas y toneladas de contenido y mantener los lectores contratados uno debe proporcionar maneras para que navegar en todo este archivo enorme de libros de catálogos de revistas y Periódicos es por eso que en cada publicación se ve un flujo interminable de cosas que usted podría estar interesado en leer a continuación aquí la cuestión principal es qué mostrar dónde y cuándo obviamente las sugerencias tienen que estar relacionados con lo que está leyendo de alguna manera y Una de esas formas es simplemente mostrar cosas similares ahora similares pueden significar patrones de lectura similares también puede significar similares en términos de contenido esta presentación es sobre la segunda de las dos opciones Por lo que el principal caso de uso aquí es encontrar si dos revistas sería considerado similar por el lector humano de todas las opciones y las siguientes diapositivas están realmente influenciados por este caso de uso así que tenga esto en cuenta a medida que avanza, pero antes incluso de que podamos hablar Acerca de las publicaciones sea similar hay que ser capaz de entender lo que la publicación es todo y para nosotros los seres humanos la tarea es muy simple vamos a sus tierras rápidas en el color solo y ya tendrá una idea bastante buena de que esto es un Revista sobre alimentos y Cocinar no es sólo una lista de ceros y también esta es una revista para que podamos abrirlo y leer lo que es información de atención y somos muy buenos en entenderlo porque tenemos un cerebro que podemos comenzar a responder a preguntas como ¿de qué se trata Lo que está relacionado con lo que se siente lo que significa que podemos hacer esto sin esfuerzo, ya que tenemos un montón de conocimientos sobre el mundo que entendemos lo que un coche es lo que es tener un cumpleaños ¿cómo se siente ser feliz En la parte superior de la que también es bueno para adaptarse a cambiar en el contexto sobre la marcha que sabemos cómo elegir el nivel adecuado de abstracción no demasiado cerca no demasiado lejos para que todo tiene sentido que podemos entender fácilmente que la misma palabra lleva un significado completamente diferente Basado en que el contexto que aparece en él se aplica a tales conceptos aparentemente objetivos como los colores el pelo rojo el vino rojo la piel derecha el libro rojo la misma palabra color completamente diferente en general tenemos esta increíble capacidad de aprender y entender diferentes temas basados en las palabras que aparecen en varios contextos Tipo de cómo los niños pequeños aprenden un idioma ahora cómo poner todo esto o ser más realista al menos parte de ella en una máquina para que podamos automatizar la búsqueda de revistas similares y también hacerlo de tal manera que las recomendaciones que se sienten casi Humanos como para empezar vamos a necesitar tres cosas primero tenemos que alimentar el conocimiento a la máquina que sea leer toneladas de cosas segundo tendrá que tener cuidado con las palabras que usamos ya que son las características que cuidan la información y, finalmente, Necesitará cerciorarse de que el conocimiento es cortado En los trozos de tamaño adecuado ya que esto determinará el contexto dentro del cual se conectarán las palabras como para
El conocimiento que podemos utilizar con seguridad Wikipedia es lo suficientemente amplia como para descargar y divertida para experimentar con wikipedia tiene artículos sobre casi cualquier cosa
Bien por lo menos todo lo que importa y mientras esta definición de digamos un cumpleaños mi difieren de lo que cada uno de nosotros está pensando en que todavía es un buen lugar para empezar no estamos construyendo un cerebro aquí, pero vamos a construir la mejor cosa siguiente Un modelo y al igual que en cualquier proceso de aprendizaje de la máquina hay cuatro partes a ser de color en primer lugar cómo procesar los datos en nuestro caso wikipedia entonces cómo entrenar el modelo real aquí es donde el LDA entrará en juego después de que tenemos que Ser capaz de aplicar el modelo en algunos nuevos datos en nuestro caso vamos a utilizar el modelo de construcción de la pedia para analizar cualquier revista y, finalmente, probablemente queremos saber si hemos tenido éxito o no decirlo por adelantado para las tres primeras partes i Han dependido en gran medida de Benson una fuente abierta tema de modelado marco maiden - el crédito aquí va a este tipo trató contra él es por lejos mi herramienta de modelado tema favorito y no podía decir suficientes cosas buenas acerca de que seguir adelante y Google en contra Ellos seguro que lo encontraremos todo bien vamos a empezar primero i descargado el wikipedia Inglés completo es en realidad alrededor de 12 conciertos si vas a conseguir algún sitio que encontrará todos los enlaces y las instrucciones theirknowledge en la wikipedia se presenta en forma de artículos Y eso es genial porque significa que ya está altamente contextualizado cada articularmente cubrir como un solo tema no es como comienza a escribir sobre el baloncesto y luego cambia a la Segunda Guerra Mundial es en realidad una característica muy importante de elegir el corpus derecho ya que el modelo asumirá que Cada pedazo de texto que alimentamos contiene dos palabras que están relacionadas de alguna manera como hablar sobre el mismo tema por lo que la estructura interna del comediante nos da un buen comienzo, pero no es perfecto la Commedia también contiene toneladas de entradas muy pequeñas con probablemente cuando me deshago De ellos no para reforzar cualquier trabajo no deseado para trabajar las conexiones más tarde elegí deshacerse de todo el artículo más corto de 200 palabras sólo para estar en el lado seguro siguiente cosa vale la pena prestar atención es que el video también tiene un montón de entradas que no son Realmente los artículos como tales, pero los metadatos se pueden identificar que estamos buscando en el título y, más específicamente, lo que comienza con he eliminado todos los intereses que comienzan con estos espacios de nombres ido ahora el corpus se redujo, pero no se preocupe, sigue siendo grande Bastante calidad sobre cantidad la cosa siguiente es recolectar todas las palabras de los artículos restantes y clasificar por la popularidad ése será nuestras solamente características observables para el modelo así que no hay crimen en ser exigente aquí también podemos comenzar quitando las palabras que aparecen en Más del diez por ciento de los artículos, así como los que son actualmente menos de 20 artículos, entonces también podemos sentir hacia mi longitud podemos aplicar diferentes stop lista que variará dependiendo de la naturaleza de la aplicación que puede incluso llevar esto más allá por la experimentación Con características como límite es una espinilla diferentes partes del habla imagínate construir un modelo que sólo reaccionaría a anunciar o peor finalmente tenemos que establecer cuántas de las palabras restantes deben quedar en el modelo y buen número para empezar es en algún lugar entre cincuenta Y cien mil ok así que ahora tenemos nuestro conjunto final de artículos que definirá la ventana de contexto y nuestro conjunto final de palabras que podemos utilizar estos dos para formar una TF idea término frecuencia inversa documento frecuencia matriz que junto con una lista de palabras Serán las dos entradas en el modelo todo esto hasta ahora fue el paso de pre-procesamiento y no puedo subrayar suficiente lo importante que esto significa la calidad de la salida será determinada por la calidad de la entrada tan claro como la basura en Basura fuera así que siempre que hicimos las elecciones correctas hasta ahora un modelo es ahora necesario para unir todo juntos contexto palabras temas En esta presentación tal modelo es el día que representa Layton declara la localización que fue desarrollada por la línea de David sus amigos y 2003 y desde entonces ha visto muchas áreas de aplicación documento clasificación sentimiento análisis incluso por informática las únicas características observables que el modelo ve realmente otros Palabras que aparecen en los documentos y hay un montón de documentos otro parámetro es un ocultado o latente inferido uno de ellos es un tema que se asigna a cada palabra que está haciendo cada documento y asegúrese de que tales temas de aviso cómo el modelo combina elegantemente las tres cosas que en realidad Lo necesito tema contexto y palabra permítanme tratar de explicarlo en mis propias palabras imaginar que en el mundo sólo tenemos tres temas política moda y deportes cada tema se expresa como una lista de palabras con probabilidades para que pertenezcan a ese tema vamos a Asumir que cualquier documento puede ser descrito por una receta de qué tema y cuánto de él debe contener por ejemplo cincuenta por ciento política treinta por ciento moda veinte por ciento deportes el modelo a continuación, generar dicho documento tomando el número correcto de palabras de temas específicos y Mezclarlos juntos lda es una bolsa de palabras modelo por lo que no hay reglas de sintaxis aquí ahora usted puede decir que no es exactamente cómo nuestras mejores obras de ficción se crearon verdad, pero hay algo de verdad en el modelo en la forma de las cosas de modelo y si tomamos Cualquier artículo y eliminar la sintaxis que definitivamente perdería bastante
Poco de información que probablemente sería ilegible para un humano, pero apuesto a que todavía podría decir si se trata de deportes o la moda por lo que de alguna manera cada documento es una colección de palabras tomadas de diferentes cubos o temas dependiendo de cuando se escribe sobre todo esto Es sólo un escenario imaginario para mostrar lo que es que el modelo asume que es el caso ahora en realidad funciona a la inversa aunque el principal es más o menos el mismo modelo toma un documento real escrito por una persona real utilizando todo tipo de palabras sintaxis Y lo que de hecho se necesita una gran cantidad de esos documentos se supone que las palabras en el mismo documento están relacionados y luego tratar trata de aprender un modelo que explicaría cómo tal colección de documentos se podría haber generado en el primer lugar si seguimos los cuatro Escenario sólo tenemos que decirle cuántos temas que deben hacer y algunas reglas adicionales sobre cómo se deben construir bien, así que tal vez las cosas no son realmente tan simple, pero de una manera muy simplificada que es cómo LD funciona algunas de las reglas adicionales que i Mencionó que el modelo modelo requiere se llaman hiperparametros alfa y mejor son ambos mejores contadores de Derrek Lee distribución alfa control / distribución de tema de documento y mejor responsable de su palabra lo sentimos nuestro tema fueron distribución un alto valor alfa significa que cada documento es probable que contenga Una mezcla de la mayoría de los temas y no sólo cualquier tema específicamente, mientras que un valor bajo de alfa significa que un documento es más probable que sea representado por sólo algunos de los temas de manera similar el mejor valor alto significa que cada tema es probable que contenga un Mezcla de la mayoría de las palabras no sólo más específicamente, mientras que un valor bajo significa que un tema puede contener una mezcla de sólo unas pocas de las palabras para ponerlo sin rodeos alto alfa hará que los documentos que son más similares entre sí y mejor Hará que los temas aparezcan más similares entre sí dada mi caso de uso, este era en realidad un efecto deseado por lo que los dos parámetros pueden ser bastante altos en caso de que me pierda algo aquí es una fórmula ahora como un resultado final LDA modelo produce este archivo que básicamente contiene todos Los temas hechos de todas las palabras con sus probabilidades de pertenecer al tema que es lo que ahora está hablando de los temas ¿cuántos se debe ir para decir que cinco 3476 realmente depende del dominio de la aplicación recuerde mi objetivo inicial no era la etiqueta o clasificar revistas Sino poder compararlos centrándose en las similitudes layton y hacer esto de tal manera que tendría sentido para un lector humano así que una vez más terminé buscando respuestas en el lado del cerebro humano ya mencioné nuestra capacidad de sentir y Aplicar el nivel adecuado de abstracción a medida que percibimos el mundo que nos rodea, pero hay mucho más cosas que hay para ser honesto No estoy seguro de si me trajo más cerca de encontrar el número real de temas a utilizar para el modelo i terminó Experimentando con varios valores a partir de 50 y llegar tan alto como 500, pero para decirte la verdad que era definitivamente interesante mirar estas cosas y tratar de entender qué es lo que prestamos atención cuando recogemos una revista o lo que hace dos de Ellos parecen elección similar En esta presentación tal modelo es el día que representa Layton declara la localización que fue desarrollada por la línea de David sus amigos y 2003 y desde entonces ha visto muchas áreas de aplicación documento clasificación sentimiento análisis incluso por informática las únicas características observables que el modelo ve realmente otros Palabras que aparecen en los documentos y hay un montón de documentos otro parámetro es un ocultado o latente inferido uno de ellos es un tema que se asigna a cada palabra que está haciendo cada documento y asegúrese de que tales temas de aviso cómo el modelo combina elegantemente las tres cosas que en realidad Lo necesito tema contexto y palabra permítanme tratar de explicarlo en mis propias palabras imaginar que en el mundo sólo tenemos tres temas política moda y deportes cada tema se expresa como una lista de palabras con probabilidades para que pertenezcan a ese tema vamos a Asumir que cualquier documento puede ser descrito por una receta de qué tema y cuánto de él debe contener por ejemplo cincuenta por ciento política treinta por ciento moda veinte por ciento deportes el modelo a continuación, generar dicho documento tomando el número correcto de palabras de temas específicos y Mezclarlos juntos lda es una bolsa de palabras modelo por lo que no hay reglas de sintaxis aquí ahora usted puede decir que no es exactamente cómo nuestras mejores obras de ficción se crearon verdad, pero hay algo de verdad en el modelo en la forma de las cosas de modelo y si tomamos Cualquier artículo y eliminar la sintaxis que definitivamente perdería bastante
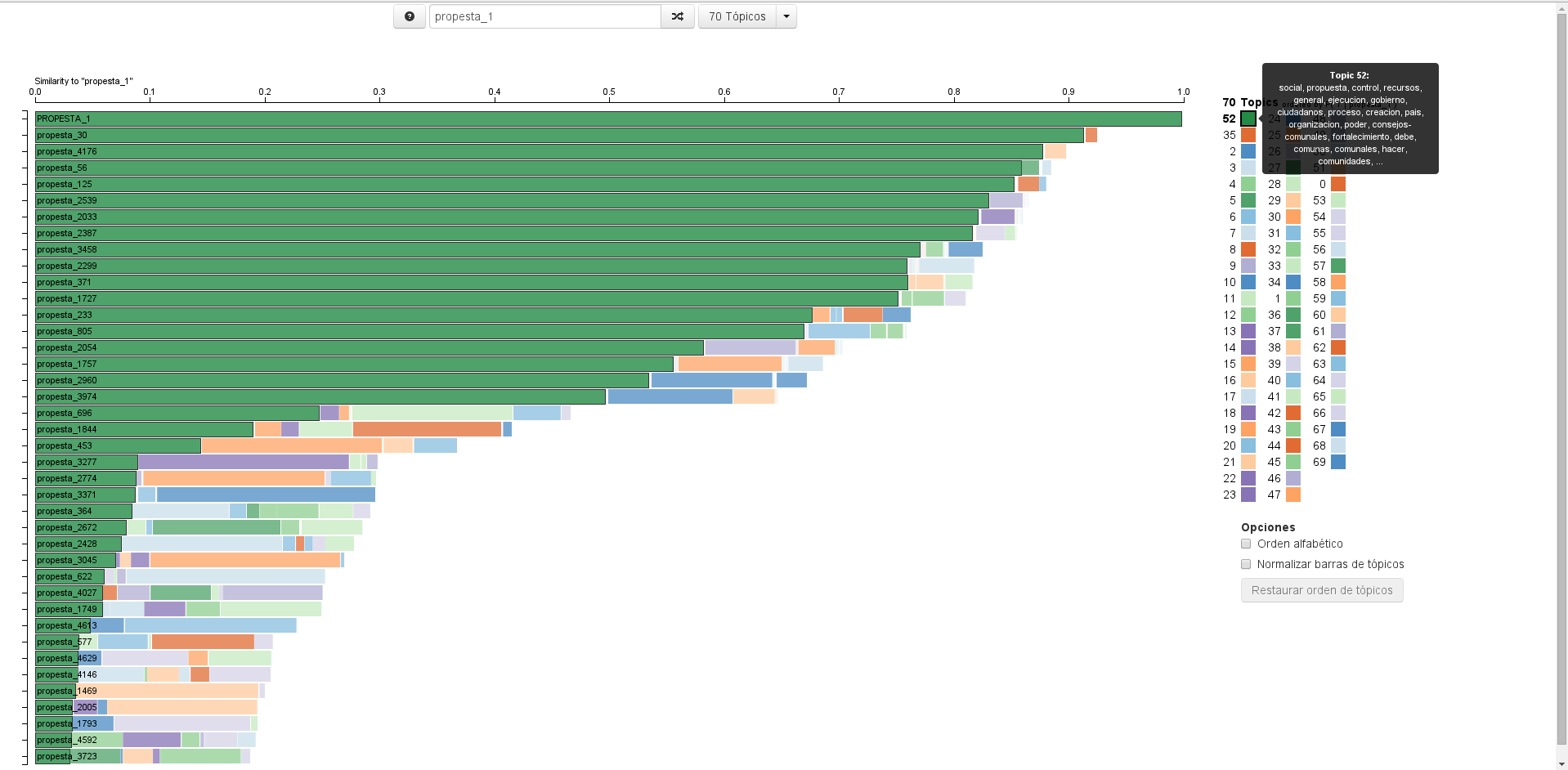
Palabras por la forma en que sólo entiende las palabras que se utilizaron para entrenar el modelo todo lo demás puede no estar allí Esta es una revista mundial de 20.000 Estoy seguro de que estaremos bien si perdemos si a lo largo del camino también Le puedo asegurar que si mi modelo entiende tan poco como el diez por ciento de las palabras en esta revista en particular es más que bien a menos que, por supuesto, hemos entrenado el modelo en el peor que llevar mejor poco significado o completamente de un dominio diferente que es por qué El corpus de texto y el preprocesamiento de la misma son probablemente los pasos más críticos para volver a la revista después de haber leído el modelo no intenta producir tal distribución de temas que explicaría mejor cómo esta revista se podría haber generado la distribución tendrá tantos temas como nosotros Pidió el modelo para hacer y la altura de las barras representan la fracción de palabras en este documento que se originó de un tema dado es una distribución de probabilidad por lo que todos los valores suman 1 ahora en lugar de centrarse en uno de los temas más dominantes que podemos Tomar como un todo un patrón único que hace que cada revista parezca lo suficientemente diferente como para ser separable, pero lo suficientemente similar como para ser agrupados, incluso podríamos decir que una revista como nosotros como un ADN ahora vamos a echar un vistazo a los temas reales aquí Por cierto esto es lo que conseguí de la gpda usando 300 temas para que puedas ver que son realmente solo una lista ordenada de palabras con sus probabilidades aviso que los temas realmente no tienen nombres o etiquetas son simplemente números Y esos números no significan nada más que un identificador único, pero somos humanos y nos gusta etiquetar las cosas por lo que es tentador hacerlo aquí, así por ejemplo tema 81 cocina top 843 vino tales etiquetas deben tomar con un montón de Precaución y en mi caso de uso ni siquiera los necesitamos ya que el objetivo no era etiquetar las revistas sino darles una huella digital significativa para que podamos compararlas una manera de comparar cosas es ponerlas en un espacio lda el espacio es un Simplex ya que estamos hablando de distribuciones de probabilidad aquí dimensionalidad del espacio depende de la cantidad de temas que les pedimos a todos hasta Maine es más fuerte un cierto tema está representado en un documento El más cercano que el documento es a esa esquina temas LD espacios a menudo tienen cientos De dimensiones que no es la cosa más fácil de visualizar aquí por razones de simplicidad este espacio tiene sólo tres temas ahora una sola revista en un espacio no significa absolutamente nada pero una vez que ponemos el resto de los 25 millones de documentos aquí se vuelve mucho más interesante si nos Tienen un espacio que puede medir la distancia y podemos medir la distancia que podemos imaginar un cierto umbral dentro del cual los documentos dentro de él serán considerados similares entre sí por la manera que las distancias pueden ser medidas usando contra y la distancia del shannon una manera estándar de medir similitud entre Dos distribuciones de probabilidad que dan los valores de 0 a trabajar es que será cerrado uno está muy lejos, así que ¿qué tenemos hasta ahora el LED de un modelo nos dan un tema de distribución para esta revista así que es bueno también tenemos algunas otras revistas que estaban cerca Suficiente en el espacio y luego incluso ordenados de acuerdo a la distancia ahora antes de entrar y evaluar los resultados vamos a aclarar qué es exactamente lo que estoy buscando el único
Adjuntos (8)
- plantuml.png (17.9 KB) - added by lchourio 7 años ago.
- Big_Data_concept_cloud_and_devices.png (127.7 KB) - added by lchourio 7 años ago.
- WordCloud1.png (158.0 KB) - added by lchourio 7 años ago.
- proceso.png (67.1 KB) - added by lchourio 7 años ago.
- entes.jpg (7.8 KB) - added by lchourio 7 años ago.
- consulta.png (18.2 KB) - added by lchourio 7 años ago.
- Figura1.png (100.8 KB) - added by lchourio 7 años ago.
- Figura2.png (386.1 KB) - added by lchourio 7 años ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip